

Whitepaper
Uncovering Real-Time Bugs with Specialized RTOS Tools
Jean Labrosse
More and more embedded systems rely on the use of Real-Time Operating Systems (RTOSes) to satisfy real-time requirements, reduce time-to-market, simplify development, increase code portability, and simplify development. Despite its many benefits, an RTOS also has its drawbacks, one of which is the possibility of introducing improperly assigned task priorities, stack overflows, starvation, deadlocks, priority inversions, and other hard-to-find bugs.
This paper will look at tools specifically designed to help RTOS-based application developers uncover some of these elusive bugs, identify issues, and offer corrective actions. These tools are readily available yet often unknown to embedded developers.
What is an RTOS?
A real-time operating system (RTOS or real-time kernel) is software that manages the time of a Central Processing Unit (CPU) as efficiently as possible. Most kernels are written in C and require a small portion of code written in assembly language to adapt the kernel to different CPU architectures. When you design an application (your code) with an RTOS kernel, you split the work into tasks, each responsible for a portion of the job. A task (also called a thread) is a simple program that thinks it has the CPU completely to itself. On a single CPU, only one task can execute at any given time. Your application code also needs to assign a priority to each task based on the task importance as well as a stack (RAM) for each task. In general, adding low-priority tasks will not affect the responsiveness of a system to higher-priority tasks. A task is also typically implemented as an infinite loop. The kernel is responsible for the management of tasks, which is called multitasking. Multitasking is the process of scheduling and switching the CPU between several sequential tasks. Multitasking provides the illusion of having multiple CPUs and maximizes the use of the CPU, as shown below. Multitasking also helps create modular applications. With a realtime kernel, application programs are easier to design and maintain.
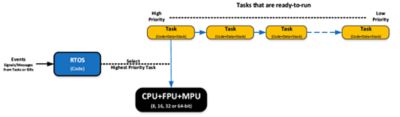
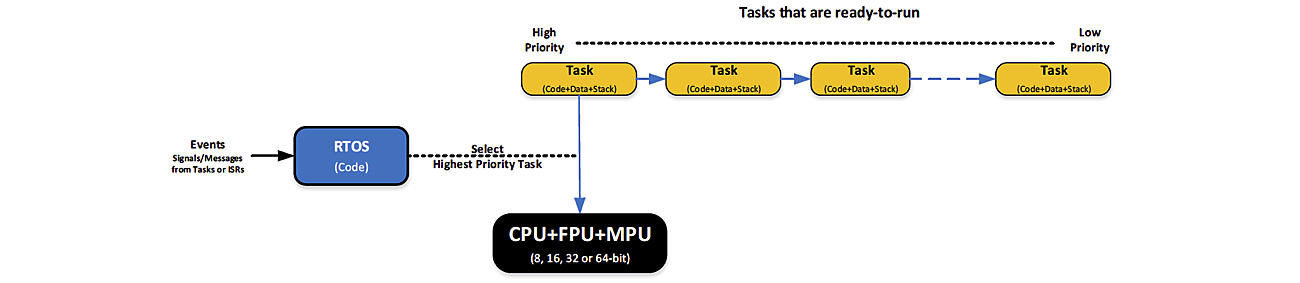
An RTOS decides which task the CPU will execute based on events
Most commercial RTOSes are preemptive, which means that the kernel always runs the most important task that is ready-to-run. Preemptive kernels are also event driven, which means that tasks are designed to wait for events to occur in order to execute. If the event that the task is waiting for does not occur, the kernel runs other tasks. Waiting tasks consumes zero CPU time. Signaling and waiting for events is accomplished through kernel Application Programming Interfaces (API) calls. Kernels allow you to avoid polling loops, which would be a poor use of the CPU’s time. Below is an example of how a typical task is implemented:


A kernel provides many useful services to a programmer, such as multitasking, interrupt management, inter-task communication and signaling, resource management, time management, memory partition management, and more. An RTOS can be used in simple applications where there are only a handful of tasks, but it is a must-have tool in applications that require complex and time-consuming communication stacks, such as TCP/IP, USB (host and/or device), CAN, Bluetooth, Zigbee and more. An RTOS is also highly recommended whenever an application needs a file system to store and retrieve data as well as when a product is equipped with some sort of graphical display (black and white, grayscale or color).
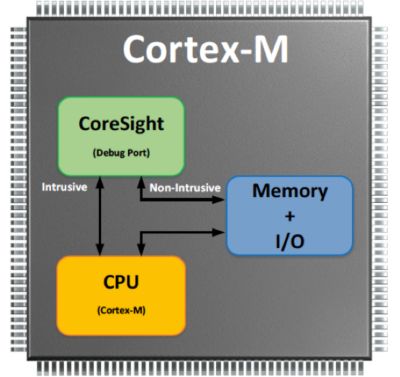
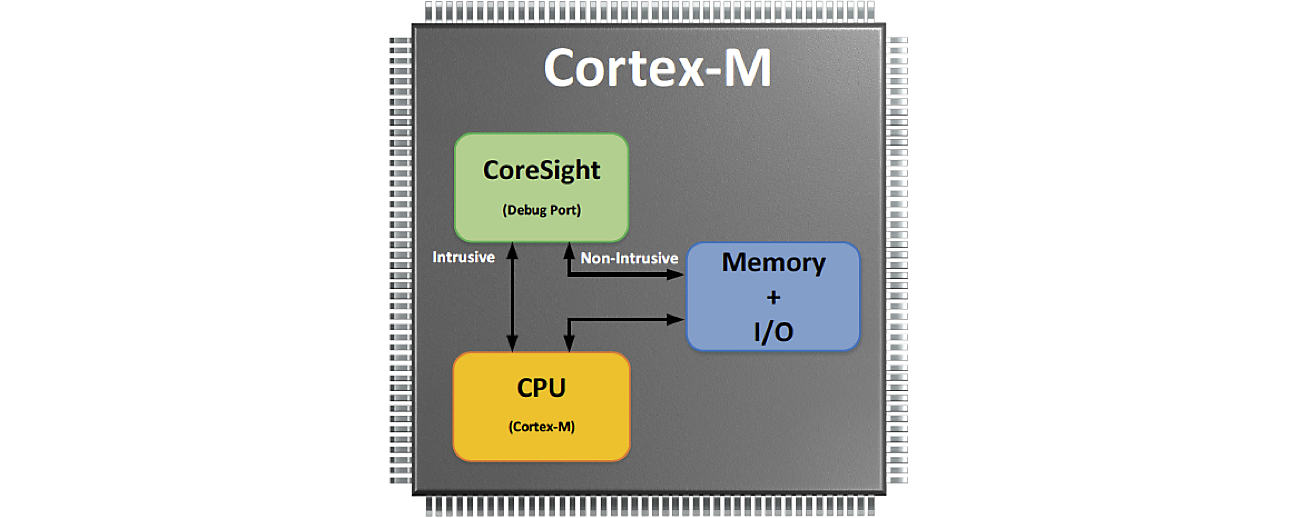
Built-In Debug Port
ARM Cortex-M processors are equipped with special and very powerful debug hardware built onto each chip. CoreSight provides non-intrusive capabilities that allow tools to monitor and control live systems without halting the CPU such as the following:
- On the fly memory/peripheral access (Read and Write)
- Instruction Trace (requires that the chip also include an Execution Trace Macrocell, ETM)
- Data Trace
- Profiling using profiling counters
The figure below shows a simplified block diagram of the relationship between the CoreSight debug port, the CPU, and Memory/Peripherals.
Tools for Testing/Debugging Live Systems
The diagram below shows how CoreSight connects to your development environment:
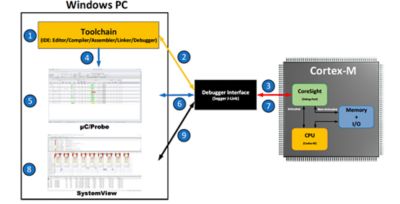
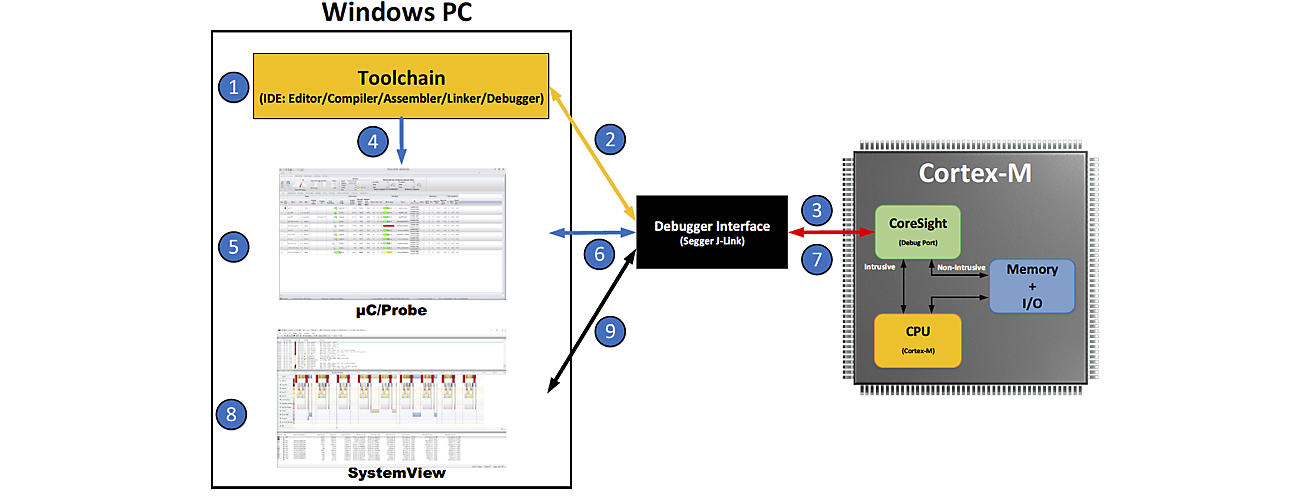
1 - Embedded developers often use an Integrated Development Environment (IDE) that includes a code editor, compiler, assembler, linker, debugger, and possibly other tools.
Debuggers built into the IDE only provide the bare necessities, such as download code, start/stop, setup breakpoints, and a few other simple features. Some debuggers go a step further and allow you to display and change variables while the target is running, such as Live Watch, but the capabilities are limited to numeric values. It’s also not uncommon for debuggers to include built-in RTOS awareness, but those typically require that you halt the application to examine the state of the RTOS (not very practical for debugging live systems).
2 - When you are ready to debug your application, download your code to the target through a Debugger Probe, such as the Segger J-Link [2].
3 - J-Link connects to the CoreSight debug port and is able to start/stop the CPU, download code, program the onboard Flash, and more. J-Link can also read and write directly to memory as needed even while the target is executing code.
4 - Micrium’s μC/Probe [3] is a standalone, CPU vendor-agnostic, Windows-based application that reads the ELF file produced by the toolchain. The ELF file contains the code that was downloaded to the target as well as the names of all globally accessible variables, their data types and their physical memory locations in the target memory.
5 - μC/Probe allows a user to display or change the value at run-time (i.e., live) of virtually any variable or memory location (including I/O ports) on a connected embedded target. The user simply populates μC/Probe’s graphical environment from a library of gauges, numeric indicators, tables, graphs, virtual LEDs, bar graphs, sliders, switches, push buttons and other components, and associates each of these with variables or memory locations in their embedded device. μC/Probe doesn’t require you to instrument the target code in order to display or change variables at run time. By adding virtual sliders or switches to μC/Probe’s screens, you can easily change parameters of your running system (such as filter coefficients and PID loop gains) or actuate devices and test I/O ports.
6 - μC/Probe sends requests to J-Link to read from or write to memory.
7 - J-Link requests are converted to CoreSight commands to obtain and display the value of variables graphically onto μC/Probe’s screens.
8 - Another highly useful tool for testing/debugging live embedded systems is SEGGER’s SystemView [4]. This tool typically works with an RTOS and displays the execution profile of your tasks and ISRs on a timeline so you can view how long each task takes to execute (minimum/average/maximum), when tasks are ready-to-run, when execution actually starts for each task, when ISRs execute, and much more. SystemView can help you uncover bugs that might go unnoticed, possibly for years. However, SystemView requires that you add code to your target (freely provided by SEGGER) that records RTOS events and ISRs. SystemView also consumes a small amount of RAM to buffer these events.
9 - J-Link allows multiple processes to access CoreSight concurrently, so you can use all three tools at once.
RTOS-Based Issues
This section explores some common issues encountered by developers when using an RTOS and shows how those can be detected and corrected.
Stack Overflow:
In a kernel-based application, each task requires its own stack. The size of the stack required by a task is application-specific [1]. You are wasting memory if you make the stack larger than the task requires. If the stack is too small, your application will most likely write over application variables or the stack of another task. Any write outside the stack area is called a stack overflow. Of course, between the two alternatives, it’s better to overallocate memory for the stack than underallocate. You can thus reduce the chances of overflowing your stacks by overallocating memory. However, 25-50% additional stack space is all that is typically needed. Some CPUs, such as those based on the ARMv8M architecture, have built-in stack overflow detection. However, that feature doesn’t help to determine the proper stack size. It just prevents the negative consequences of stack overflows.
Reference [1] explains how to determine the size of each task stack. In a nutshell, you start your design by overallocating space for your task stacks, then run your application under its known worst-case conditions while monitoring actual stack usage.
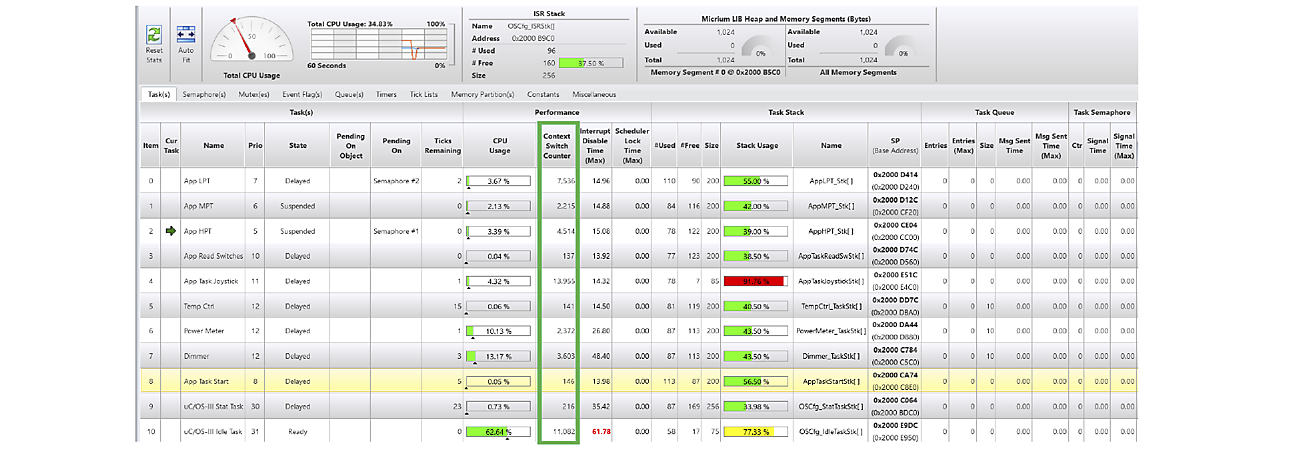
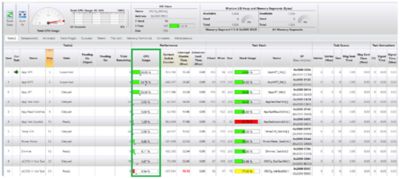
The figure below shows a screenshot of μC/Probe’s kernel awareness of a test application. The Stack Usage column shows a bar graph of the maximum stack usage at any given time for each task. Although a screenshot was taken, μC/Probe updates and displays this information live so you don’t have to stop the target to view this information as it’s being updated.
Green indicates that the maximum stack usage has been kept below 70%.
Yellow indicates that stack usage is between 70% and 90%.
Red indicates that stack usage has exceeded 90%.
Clearly, the stack for the task that uses 92% should be increased to bring it back below the 70% range. The task stack that is Yellow is the idle task, and, at 77%, it will generally not be an issue unless you add code to the idle task callback function (this depends on the RTOS you use).
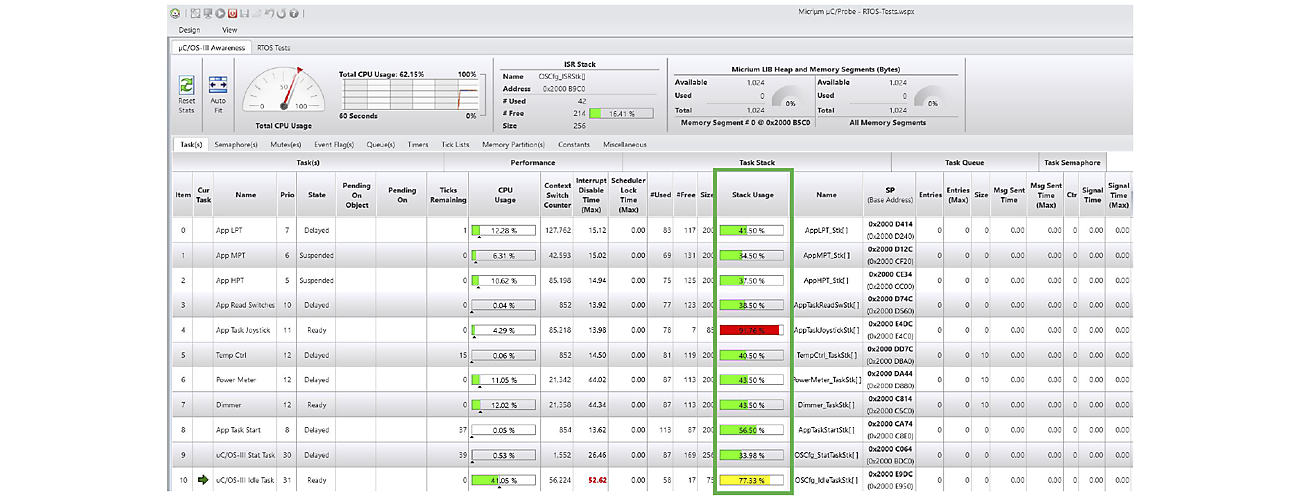
Sizing Task Stacks to Prevent Overflows
Interrupt Response:
RTOSes and application code often have to disable interrupts when manipulating internal data structures (i.e., critical sections). RTOS developers make every attempt to reduce the interrupt disable time as it impacts the responsiveness of the system to events.
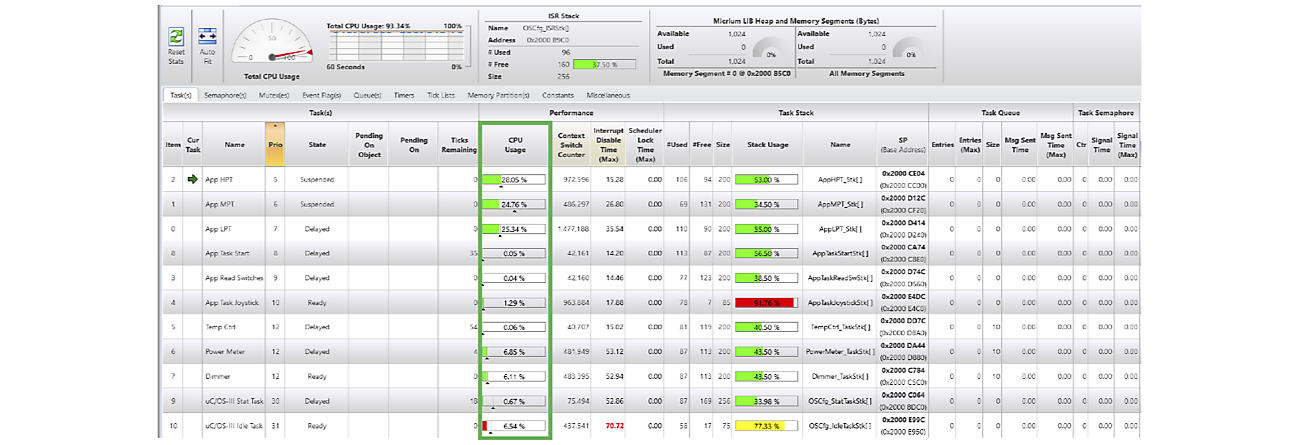
Some RTOSes actually measure the worst-case interrupt disable time on a per-task basis as shown in the μC/Probe screenshot below. This information is invaluable if you are trying to satisfy real-time deadlines.
The amount of time interrupts are disabled greatly depends on the CPU, its clock rate, your application, and the RTOS service being invoked. The
task that disables interrupts the longest is highlighted in Red. This allows you to quickly identify potential outliers, especially in large and complex applications.
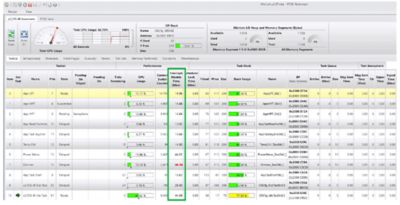

Displaying Maximum Interrupt Disable Times
If the largest interrupt disable time is caused by the RTOS, you might not be able to do much about it except possibly the following:
- Find alternate RTOS APIs with lower interrupt disable times. For example, if you are only signaling a task to indicate that an event occurred, you might suspend/resume the task instead of using a semaphore or event flag. In other words, the task waiting for the event suspends itself and the ISR that signals the event resumes the task.
- Increase the clock rate of your CPU. Unfortunately, this is rarely an option since other factors might have decided the ideal CPU clock frequency.
- Use non-Kernel Aware interrupts to handle your highly time-sensitive code.
Priority Inversions
Priority inversion occurs when a low-priority task holds a resource that a high-priority task needs. The problem is aggravated when medium-priority tasks preempt the low-priority task while it holds the resource. The term “priority inversion” refers to the fact that a low priority task acts as if it had a higher priority than the high-priority task, at least when it comes to sharing that resource.
Priority inversions are a problem in real-time systems and occur when using a priority-based preemptive kernel (most RTOSs are preemptive). As
shown in the diagram below, SystemView is used to illustrate a priority-inversion scenario.
App HPT (High Priority Task) has the highest priority
App MPT (Medium Priority Task) has a medium priority
App LPT (Low Priority Task) has the lowest priority
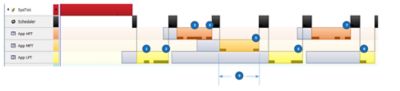

Priority Inversion Caused when Using a Semaphore to Share a Resource
1 - The LPT is the only task that is ready-to-run, so it gets the CPU and acquires asemaphore to gain access to a shared resource.
2 - To simulate the occurrence of a priority inversion, the LPT makes the HPT ready-to-run, and, therefore, the RTOS context switches to the HPT.
3 - The HPT makes the MPT ready-to-run but keeps executing because the HPT still has a higher priority.
4 - The HPT needs to access the shared resource and attempts to acquire the semaphore. However, because the semaphore is owned by the LPT, the HPT cannot continue executing, so the RTOS switches to the MPT.
5 - The MPT executes until it needs to wait for its event to reoccur so the RTOS switches back to the LPT.
6 - The LPT finishes its use of the shared resource, so it releases the semaphore. At this point, the RTOS notices that the HPT is waiting for the resource and gives the semaphore to the HPT and makes it ready-to-run. The HPT resumes execution and performs whatever operation it needs to perform on the shared resource.
7 - Once the HPT finishes accessing the resource, it releases the semaphore and then waits for its event to reoccur (in this case, this is simulated with a self-suspend).
8 - The LPT resumes execution because neither of the other two tasks are ready-to-run.
9 - The priority inversion occurs because an LPT holds a resource that the HPT needs. However, the problem gets worse when medium-priority tasks further delay the release of the semaphore by the LPT.
You can solve the priority inversion issue described above by using a special RTOS mechanism called the Mutex (Mutual Exclusion Semaphore). The figure below shows the same scenario, except here the LPTand HPT both use the mutex to gain access to the shared resource instead of a semaphore.


Eliminating Unbounded Priority Inversions with Mutexes
1 - The LPT is the only task that is ready-to-run, so it gets the CPU and acquires a mutex to gain access to a shared resource.
2 - To simulate the occurrence of a priority inversion, the LPT makes the HPT ready-to-run, and thus the RTOS context switches to the HPT.
3 - The HPT makes the MPT ready-to-run but keeps executing because the HPT still has a higher priority.
4 - The HPT needs to access the shared resource and attempts to acquire the mutex. However, since the mutex is owned by the LPT, the HPT cannot continue executing. However, because a mutex is used, the RTOS will increase the priority of the LPT to that of the HPT to prevent it from being preempted by medium priorities.
5 - The RTOS then switches to the LPT, which now runs at the same priority as the HPT.
6 - The LPT finishes its use of the share resource, so it releases the mutex. The RTOS lowers the LPT’s priority back to its original (lower) priority and assigns the mutex to the HPT.
7 - The RTOS switches back to the HPT since it was waiting for the mutex to be released. Once done, the HPT releases the mutex.
8 - Once the HPT finishes execution of its work, it waits on the reoccurrence of the event it is waiting for.
9 - The RTOS switches to the MPT, which was waiting in the ready queue.
10 - When the MPT completes its work, it also pends on the event that will cause this task to execute again.
11 - The LPT can now resume execution.
The priority inversion is now bounded to the amount of time the LPT needs to access the shared resource. Priority inversions would be very difficult to identify and correct without a tool like SystemView.
Note that you can use a semaphore if the LPT was just one priority level below the HPT. A semaphore is preferred, in this case, because it’s faster than a mutex since the RTOS would not need to change the priority of the LPT.
Deadlocks:
A deadlock, aslo known as a deadly embrace, occurs when (at least) two tasks are each unknowingly waiting for a resource that the other holds. The deadlock may not happen immediately since a lot depends on when both tasks need each other’s resource. As shown below, μC/Probe’s kernel awareness screen has a column that shows how often each task executed (i.e., how often the task was switched in by the RTOS). You can detect a deadlock by monitoring this column and notice if any of the tasks you are expecting to run are in fact running. In other words, if the counting stops (μC/Probe updates these counters while the CPU is running), it’s possible you detected a deadlock. For this to be the case, however, you will also notice that the counting stopped for at least two tasks. You might not need to use a tool like μC/Probe to detect deadlocks since, in any case, you ought to notice the lockup behavior of those tasks in your application. However, the tool makes it more obvious.
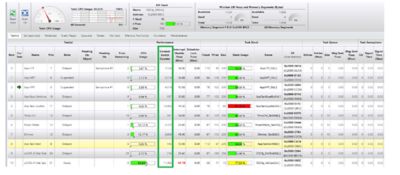
Detecting Deadlocks
You can avoid deadlocks by doing the following:
- Always acquiring all required resources and always acquiring them in the same order and releasing them in the reverse order.
- Using timeouts on RTOS API calls to avoid waiting forever for the resource to be available. Make sure you examine the return error code from the RTOS API to ensure that your request to the desired resource was indeed successful.
Starvation:
Starvation occurs when high-priority tasks consume all the CPU’s bandwidth leaving little or no CPU time for lower priority tasks. Effects of starvation are characterized by a degradation in responsiveness and product features, such as the display of your embedded target updating slowly, loss of packets in communications stacks, sluggish operator interface, etc. There is little you can do to fix these issues other than the following:
- Optimize the code that consumes most of the CPU’s bandwidth.
- Increase the CPU’s clock speed. This is seldom an option because of other system considerations.
- Select another CPU. This is also rarely an option, especially late in the development cycle.
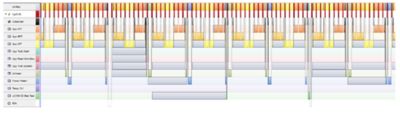
Heavily Loaded Application, Sorted by Priority
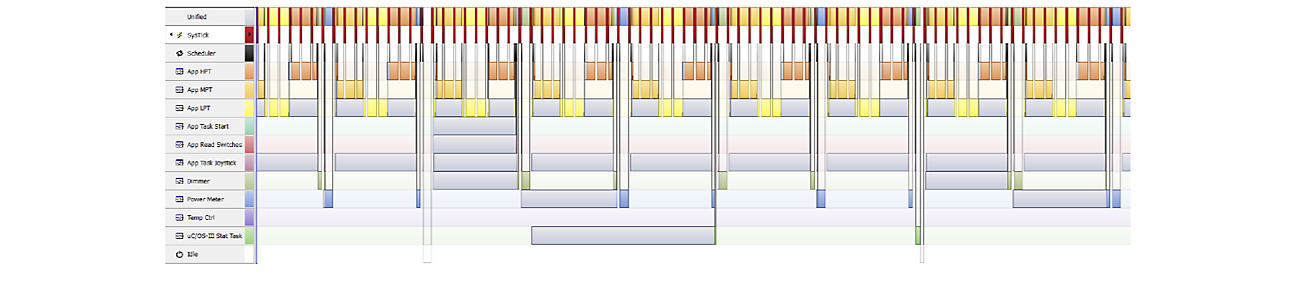
SystemView Showing a Heavily Loaded Application
Monitoring Task and ISR Execution Times
It is often useful to know the execution time of tasks and ISRs to help with RTOS-based system analysis, such as Rate Monotonic Analysis (RMA). Specifically, with this information, you can determine whether all time-critical tasks can meet their deadlines as well as help you assign priorities for tasks. Unfortunately, this information is only truly accurate and available after a system has been designed and run. In other words, the actual execution time of code is often not accurately known until it is executed on the actual target. However, once available, task and ISR execution times are highly useful to confirm assumptions made during system design.
SystemView provides min/max execution times of both tasks and ISRs as shown in the screenshot below.
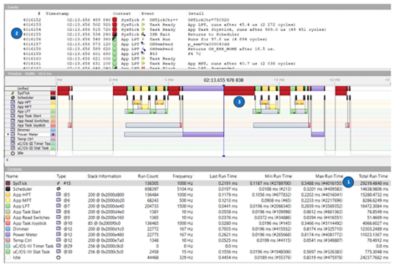
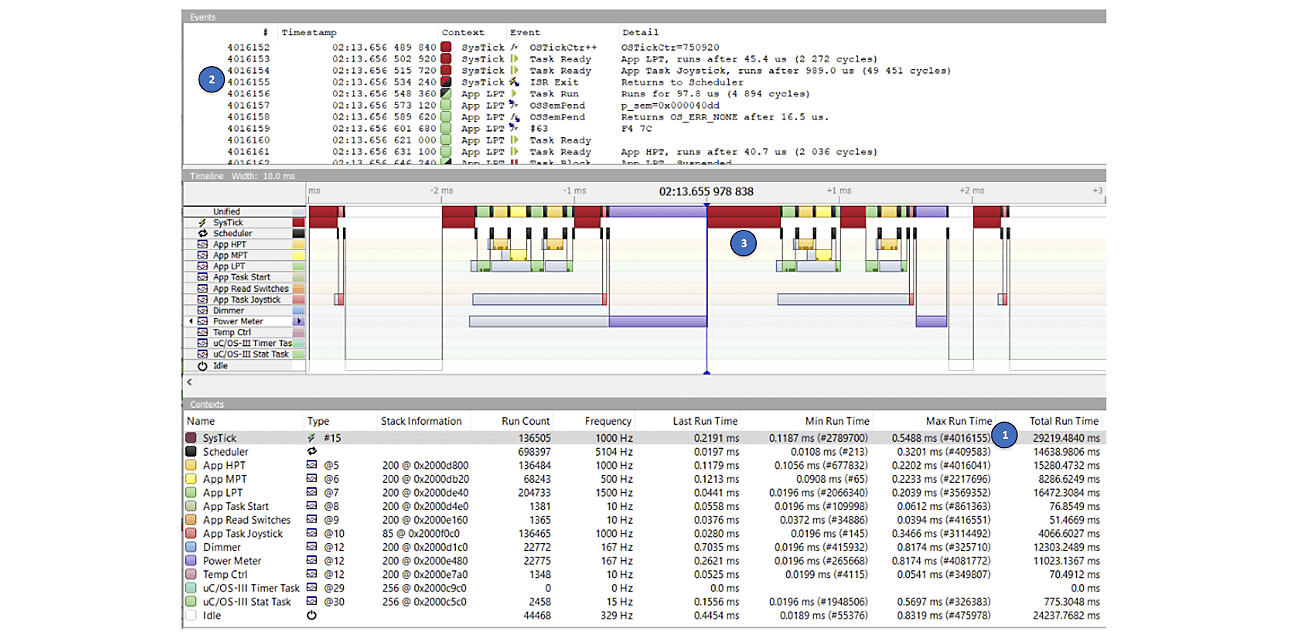
1 - The Max Run Time column in the Context pane shows the maximum execution time of all the tasks and ISRs. In the case of the SysTick (i.e., the tick ISR), the longest execution time was 0.5488 ms. You can determine when (in time) this longer execution time occurred by searching for Event #4016155. You would select Go to event from the Go menu and type 4016155 followed by Enter.
2 - The Events window shows that this corresponds to the ISR exit. In fact, this makes sense as the maximum execution time of the ISR is only known when the ISR exits.
3 - Double-clicking on the line showing event #4016155 in the Events window forces the Timeline window to show that event. As can be seen, the SysTick execution is wider than other execution times.
In most cases, you don’t need to find where (in time) the maximum execution time of a task or ISR occurred, especially if you are only using that information for RMA. However, in some cases, you might need to find out why execution time took substantially longer than anticipated or expected. Unfortunately, SystemView might not be able to provide additional clues as to the reason this is happening. This is where you might want to use a code execution trace tool, such as Segger’s J-Trace and examine the code executed by the ISR prior to event #4016155.
Measuring Execution Time of User Code
There are many ways to measure code execution time. One way is to use a trace-capable debug probe. Run the code, look at the trace, compute the delta time (typically manually), and convert CPU cycles to microseconds. Unfortunately, the trace gives you one instance of execution, and you might have to look further down the trace capture to find the worst-case execution time. This can be a tedious process. Another way is to instrument your code and take snapshots of an available free-running counter at different places in your code and calculate the difference between snapshot readings. This was actually described in a paper published in Embedded Computing Design [7] for Cortex-M MCUs, but the concept applies equally well for other targets. The paper provides APIs to measure elapsed times. You wrap the code to measure, as follows:
elapsed_time_start(n);
// Code to measure
elapsed_time_stop(n);
Where “n” specifies one of “n” bins (0 to n-1) where the minimum and maximum execution times are saved, as follows:
elapsed_time_tbl[n].min
elapsed_time_tbl[n].max
For Cortex-M, the execution times are saved in CPU clock frequency units.
As shown below, you can use Micrium’s μC/Probe to easily display the results in microseconds. μC/Probe allow numbers to be scaled, and, in this case, the adjustment is made to account for the CPU clock frequency of the evaluation board used.


Displaying Min/Max/Currrent Execution Times of Portions of Code with μC/Probe
Summary
Debuggers built into IDEs are often insufficient to debug live RTOS-based systems.
Fortunately, there are specialized tools designed specifically for debugging RTOS-based systems, yet these are often unknown to developers. One of these tools is Segger’s SystemView [4], which displays ISRs and tasks on a timeline as well as gathering run-time statistics, such as minimum and maximum execution times, relationship between ISRs and tasks, CPU load and more.
Another tool that can compliment SystemView is Micrium’s μC/Probe [3], which is a general-purpose tool that allows the developer to visualize and alter the behavior of a running embedded target without interfering with the CPU. μC/Probe works equally well in bare metal or RTOS-based applications. For RTOS-based applications, μC/Probe includes non-intrusive, live kernel awareness as well as TCP/IP stack awareness. Both types of tools (SystemView and μC/Probe) should be used early and throughout the development cycle to provide feedback about the run-time behavior of embedded targets.
References
[1] Jean Labrosse, “Detecting Stack Overflows (Part 1 and Part 2)”.
https://www.micrium.com/detecting-stack-overflows-part-1-of-2
https://www.micrium.com/detecting-stack-overflows-part-2-of-2
[2] SEGGER, “Debug Probes,”
https://www.segger.com/jlink-debug-probes.html
[3] Micrium, “μC/Probe, Graphical Live Watch.,”
https://micrium.com/ucprobe/about
[4] SEGGER, “SystemView for μC/OS,”
https://www.micrium.com/systemview/about
www.segger.com/systemview.html
[5] Silicon Labs, “Simplicity Studio”
http://www.silabs.com/products/development-tools/software/simplicity-studio
[6] Percepio, “Tracealyzer”
[7] Jean Labrosse, “Measuring code execution time on ARM Cortex-M MCUs”
https://www.embedded-computing.com/hardware/measuring-code-execution-time-on-arm-cortex-m-mcus