

Whitepaper
How MPUs Can Help You Make Products Safer and More Secure
Jean Labrosse
A Memory Protection Unit (MPU) is hardware that improves the safety and security of an embedded device by only allowing access to memory and peripheral devices to the code that needs to access those resources. The application can be organized by processes, each having access to its own memory and peripheral space. Not only does the MPU prevent application code from accessing memory or peripheral devices outside its designated area, but it can also be a useful tool for detecting stack overflows, one of the most common causes of issues when using an RTOS.
This document discusses some of the features provided by most MPUs, but specific examples assume the MPU found in most ARM Cortex-M MCUs. Topics covered include the following:
- Privilege modes
- Limiting RTOS APIs for user code
- Preventing code from executing out of RAM
- Sharing data
- Keeping RTOS objects in RTOS space
- Handling faults
What is an RTOS?
A real-time operating system (an RTOS or a real-time kernel) is software that manages the time of a Central Processing Unit (CPU) as efficiently as possible. Most kernels are written in C and require a small portion of code written in assembly language to adapt the kernel to different CPU architectures. When you design an application (your code) with an RTOS kernel, you split the work into tasks, each responsible for a portion of the job. A task, also called a thread, is a simple program that thinks it has the CPU completely to itself. On a single CPU, only one task can execute at any given time. Your application code also needs to assign a priority to each task based on the task importance as well as a stack (RAM) for each task. In general, adding low-priority tasks will not affect the responsiveness of a system to higher-priority tasks. A task is also typically implemented as an infinite loop. The kernel is responsible for the management of tasks. This is called multitasking. Multitasking is the process of scheduling and switching the CPU between several sequential tasks. Multitasking provides the illusion of having multiple CPUs and maximizes the use of the CPU, as shown below. Multitasking also helps creating modular applications. With a realtime kernel, application programs are easier to design and maintain.
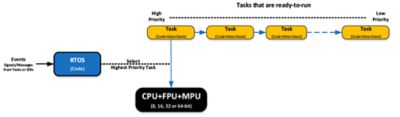
An RTOS decides which task the CPU will execute based on events
Most commercial RTOSes are preemptive, which means that the kernel always runs the most important task that is ready-to-run. Preemptive kernels are also event driven, which means that tasks are designed to wait for events to occur to execute. If the event that the task is waiting for does not occur, the kernel runs other tasks. Waiting tasks consumes zero CPU time. Signaling and waiting for events is accomplished through kernel Application Programming Interfaces (API) calls. Kernels allow you to avoid polling loops, which would be a poor use of the CPU’s time. Below is an example of how a typical task is implemented:

A kernel provides many useful services to a programmer, such as multitasking, interrupt management, inter-task communication and signaling, resource management, time management, memory partition management, and more. An RTOS can be used in simple applications with only a handful of tasks, but it is a must-have tool in applications that require complex and time-consuming communication stacks, such as TCP/IP, USB (host and/or device), CAN, Bluetooth, Zigbee, and more. An RTOS is also highly recommended whenever an application needs a file system to store and retrieve data as well as when a product is equipped with some sort of graphical display (black and white, grayscale, or color).
For performance reasons, most RTOSes are designed to run application code in privileged mode (Supervisor mode), therefore allowing those applications full control of the CPU and its resources. This is illustrated below where all tasks and ISRs have unrestricted access to memory and peripheral devices. Unfortunately, this implies that application code can accidently or purposely corrupt the stacks or variables of other tasks. In addition, allowing any task or ISR full access to all peripheral devices can have dire consequences.
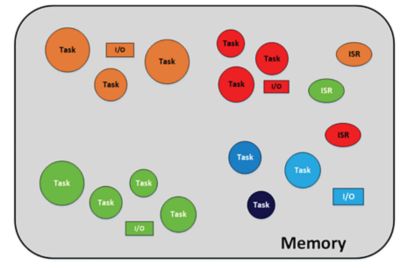
An RTOS and application code running with full privileges (without an MPU)
What is an MPU?
A Memory Protection Unit (MPU) is hardware that only allows access to memory and peripheral devices to the code that needs to access those resources. An MPU enhances both the stability and safety of embedded applications and is therefore often used in safety-critical applications, such as medical devices, avionics, industrial control, nuclear power plants, etc. MPUs are now finding their way into the Internet of Things (IoT) because limiting access to memory and peripherals can also improve product security. Specifically, crypto keys can be hidden from application code to deny attackers access. Isolating the flash memory controller with the MPU can also prevent an attacker from changing an application, therefore allowing only trusted code to perform code updates.
With the help of an MPU, RTOS tasks are grouped into processes, as shown below. Each process can consist of any number of tasks. Tasks within a process are allowed to access memory and peripherals that are allocated to that process. However, a task doesn’t know that it’s part of the same process except for the fact that it is given access to the same memory and I/Os as other tasks within the process. When you add an MPU, very little has to change from a task’s perspective since your tasks should be designed in such a way that they don’t interfere with each other unless they have to.
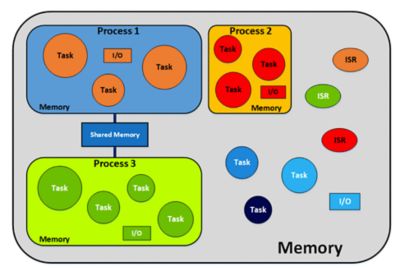
Separating an application into multiple processes
As shown above, processes can communicate with one another through shared memory. In this case, the same region(s) would appear in the MPU configuration table for both processes.
An application can also contain system-level tasks and ISRs with full privileges, therefore allowing them to access any memory location, peripheral device or the CPU itself.
Exactly what happens when such a violation occurs greatly depends on the application and, to a certain extent, which task caused the violation. For example, if the violation is caused by a graphical user interface (GUI), terminating and restarting the GUI might be acceptable and might not affect the rest of the system. However, if the offending task controls an actuator, the exception handler might need to immediately stop the actuator movement before restarting the task. Ideally, access violations are caught and corrected during product development because, otherwise, the system designer would need to assess all possible outcomes and make decisions on what to do when this happens in the field. Recovering from an MPU violation can get quite complicated.
Detecting Stack Overflows with an MPU
In RTOS-based applications, each task requires its own stack. Stack overflows are probably one of the most common issues facing developers of RTOS-based systems. Without hardware assistance, stack overflow detection is performed by software and is, unfortunately, rarely caught in time, which potentially makes the product unstable, at best. The MPU can help protect against stack overflows but, unfortunately, is not ideal.
As shown below, an MPU region can be used to detect stack overflows. In this case, a small region is used to overlay the bottom of each task stack. The MPU attributes are configured such that the MPU generates an exception if any code attempts to write to that region. The size of the region determines how effective this technique will be at catching a stack overflow. The larger the region, the greater the chance a stack overflow will be caught, but, at the same time, the less RAM will be available for the stack. In other words, the RedZone would be considered unusable memory because it’s used to detect illegal writes. A good starting point for the RedZone size would be 32 bytes. If your task stack is 512 bytes, 32 bytes would only represent about 6 percent, leaving 480 bytes of usable stack space.
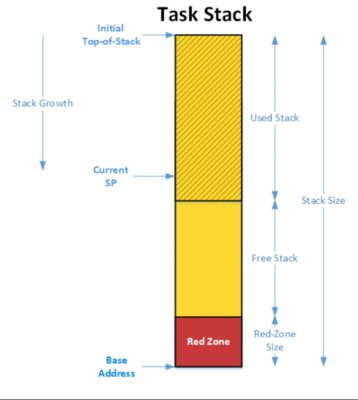
MPU region used to detect stack overflows
Below is an alternate method of detecting stack overflows. Here, the whole task stack is wrapped by an MPU region, and reads and writes are allowed. There are two problems with this method: First, at least in the case of Cortex-M (ARMv7M architectures), the size of each stack needs to be a power of two and it must be aligned on the same power-of-two boundary (i.e., 32, 64, 128, 256, 512, etc). If the embedded application has plenty of RAM at its disposal, then this is not really an issue. However, in resource-constrained applications (typical of Cortex-M MCUs), it might be complicated to set up stack memory while reducing waste. Second, writes to stacks of other tasks within the same process are not allowed. However, in most cases, this is not an issue unless tasks within a process pass information through each other’s stacks.
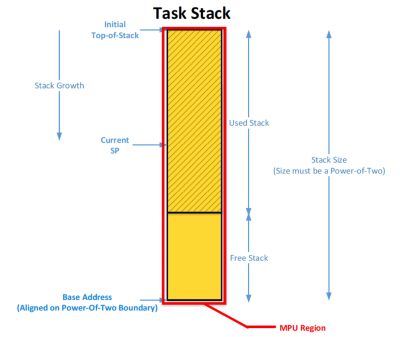
Alternate method of detecting stack overflows
The Process Table
The number of entries in the process table depends on the MPU. MCUs within the Cortex-M family can have either eight or 16 regions. Because of the fairly limited number of regions available in an MPU, they are generally set up more to prevent access to data (in RAM) than to prevent access to code (in flash). However, if your application doesn’t use all the regions, security will also be improved by limiting access to code.
The diagram on the next page shows the regions defined for a process containing four tasks. Only the memory associated with the process is shown. Other processes have their own memory areas, although, in most cases, they will all share the same code space (i.e., flash).
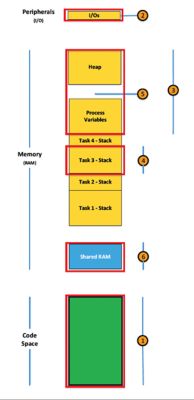
MPU regions used for a process with four tasks
- One MPU region is used to provide read and execute access to code space. Read access is necessary because constants are often stored in flash (ASCII strings, look-up tables, constants, etc.).
- A region is used to provide tasks within a process to access peripheral devices associated with the process. For example, an ethernet controller, a USB controller, etc. An MPU region is not necessary if the process is compute-bound and doesn’t require access to peripheral devices. In this case, the MPU region would be set up for read/write access but disallow code execution.
- An MPU region is used to wrap process-specific global variables as well as a process heap, as needed. The MPU region would be set up for reads and writes but, again, would disallow code execution.
- An MPU region is used to detect stack overflows. As previously mentioned, this method assumes that tasks within a process don’t share data through their stacks. Again, code execution would be disallowed in this region. The RTOS is responsible for selecting which task is allowed to run and, therefore, which task stack will be wrapped in an MPU region.
- This area shows possible RAM waste because of the MPU region size restrictions and alignment. Attempts should be made to minimize waste in resource-constrained embedded applications.
- This MPU region is used to establish shared RAM with one or more other processes. If the process doesn’t need to share data, there is no need to dedicate an MPU region.
The process table consist of “N” entries, where each entry contains two fields: the base address of the region and attributes specifying the size of the region (whether the region allows reads, writes or executes, or other attributes).
The process table is typically assigned to a task when the task is created. The RTOS keeps a pointer to the process table in the Task’s Control Block (TCB). An RTOS context switch now includes additional code to update the MPU with the process table of the task being switched-in, as shown below. You will notice that the MPU configuration doesn’t need to be saved when a task is switched-out since the configuration for the task is always loaded from the process table, which is typically placed in ROM (i.e., flash).
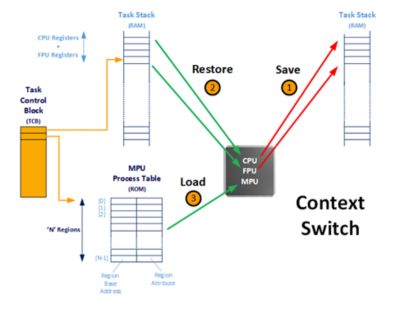
The configuration of the MPU is updated by the RTOS during a context switch
Cortex-M Privilege Levels
At power up, the Cortex-M starts in privileged mode, giving it access to all CPU features. It can access any memory or I/O location, enable/disable interrupts, set up the nested vectored interrupt controller (NVIC), and configure the FPU and MPU, etc.
To keep a system safe and secure, privileged mode code must be reserved for code that has been fully tested and is trusted. Because of the thorough testing that most RTOSes undergo, they are generally considered trusted while most application code is not. There are a few exceptions to this practice. ISRs, for example, are typically assumed to be trusted and, as a result, are also run in privileged mode, as long as those ISRs are kept as short as possible and not abused. This is a typical recommendation from most RTOS vendors.
Application code can be made to run on a Cortex-M in non-privileged mode, therefore restricting what the code can do. Specifically, non-privileged mode prevents code from disabling interrupts, changing the settings of the nested vectored interrupt controller (NVIC), changing the mode back to privileged, and altering MPU settings, as well as a few other things. This is a desirable feature because you don’t want untrusted code to give itself privileges and therefore change the protection put in place by the system designer.
Because the CPU always starts in privileged mode, tasks need to be either created from the start to run in non-privileged mode or switched to non-privileged mode (by calling an API) shortly after starting. After it is in non-privileged mode, the CPU can only switch back to privileged mode when servicing an interrupt or an exception.
Access to RTOS Services from User Code
Because non-privileged code cannot disable interrupts either through the CPU or the NVIC, application code is forced to use RTOS services to gain access to shared resources. Because RTOS services need to run in privileged mode (to disable interrupts during critical sections), nonprivileged tasks must pass through a special mechanism on the Cortex-M, called the SuperVisor Call (SVC) to switch back to privileged mode. The SVC behaves like an interrupt but is invoked by a CPU instruction. This is also known as a software interrupt.
Because RTOS services need to run in privileged mode (to disable interrupts during critical sections), nonprivileged tasks must pass through a special mechanism on the Cortex-M called the SuperVisor Call (SVC) to switch back to privileged mode.
On the Cortex-M, the SVC instruction uses an 8-bit argument to specify which of 256 possible RTOS functions (or services) the caller wants to execute. The system designer decides what RTOS services should be made available to non-privileged code. For example, you might not want to allow a non-privileged task to terminate another task (or itself). Also, none of these services would allow interrupts to be disabled since that would defeat one of the purposes of running code in nonprivileged mode. Once invoked, the SVC instruction vectors to an exception handler called the SVC Handler.
This process is shown in the diagram below.
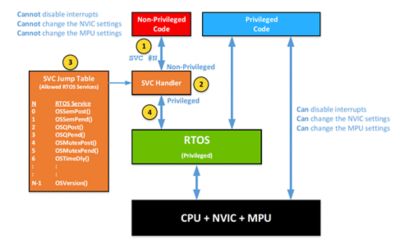
Invoking RTOS Services from User (i.e., Non-Privileged) Code
If non-privileged code wants to wait on a mutex (i.e., call OSMutexPend()), it will invoke SVC #5.
- The SVC instruction forces the SVC exception handler to execute. The behavior is the same as if an interrupt was generated.
- The SVC handler extracts the argument (i.e., the value 5) and uses that to index into the SVC Jump Table.
- The desired RTOS service is executed (in privileged mode), and, upon completion, the RTOS returns to the non-privileged code.
- The SVC handler is part of the RTOS, so you don’t have to worry about having to implement it. In fact, your application code will invoke the same RTOS APIs whether your task runs in privileged or non-privileged mode.
On the Cortex-M3, the SVC handler adds about 1 kbytes of code and requires between 75 and 125 CPU instructions to execute. So, any RTOS service invoked by non-privileged code will require more processing time than the same RTOS service called from privileged mode.
Running code in non-privileged mode also prevents user code from disabling interrupts, therefore reducing the chances of locking up the system. Of course, lockups are still possible if user code gets into an infinite loop, especially when that happens in a high-priority task or ISR. However, a lockup can be recovered (in this case, through the use of a Watchdog).
Interprocess Communications
The figure below shows different ways that processes can communicate with each other. These are just some of the possible scenarios, and, in fact, an application can use a combination of the techniques described below. The Cortex-M also has special instructions to allow lock-free data structures; this makes shared access simple and efficient but assumes non-blocking.
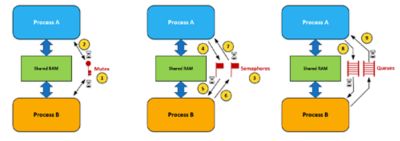
Interprocess communications
- A mutex is used to ensure that two processes do not access the same data at the same time. You should note that the mutex actually resides in RTOS memory space, and, through RTOS APIs, the mutex is accessible to either process. Of course, there could be multiple mutexes, each providing access to different resources shared by two (or more) processes.
- Tasks needing access to a shared resource guarded by the mutex must first acquire the mutex. After the task finishes accessing the shared resource, the mutex is released. The hourglass represents an optional timeout if a task is not willing to wait forever for the mutex to be released by its current owner.
- Semaphores can also be used by processes to signal each other about data availability.
- A task within Process A deposits data into an agreed-upon area in the shared RAM and then signals the semaphore on the left.
- A task within Process B waits for the signal from Process A through the semaphore. A signal indicates that data is available. Again, the hourglass represents an optional timeout to avoid waiting forever for a signal. If the signal doesn’t occur within the timeout period, the task is resumed by the RTOS. In this case, however, the task knows that nothing has been deposited in the shared area.
- Process B can acknowledge the fact that it processed the data (if a timeout didn’t occur).
- After signaling the semaphore, Process A waits for an acknowledgement with an optional timeout.
- Alternatively, communication can use an RTOS’s message queue mechanism. In this case, a buffer from dynamically allocated memory is obtained from the shared RAM area (the buffer needs to be accessible by both processes). The sender task in Process A fills the buffer and sends a pointer to a task in Process B.
- Similar to the semaphore case, the task in Process B can wait for a reply and specify an optional timeout.
Handling Memory or I/O Access Faults
As previously mentioned, the job of the MPU is to ensure that tasks within processes only access memory or peripheral devices that are assigned to them. But, what if these tasks attempt to access data outside of those regions? In that case, the MPU triggers a CPU exception called the Memory Manage (MemManage) Fault.
What happens when a fault is detected greatly depends on the application and is probably one of the more difficult things to determine. Needless to say, these types of faults should be detected and corrected during development. However, one of the reasons for using the MPU is to protect against an invalid memory or peripheral access occuring in the field, either because of some corner case that was not caught during system verification or through unauthorized access.
The MemManage fault is generally handled by the RTOS. Ideally, your embedded system has some mechanism to record and report faults to developers so that corrections (if needed) can be included in the product’s next release. A file system is a good place to record these faults, assuming, of course, that it can still be relied upon by the fault handler.
When a fault occurs, the fault handler can perform the following sequence of operations (shown in the pseudo code below):
void OS_MPU_FaultHandler (void)
{
// Terminate the offending task/process (1)
// Release resources owned by the task/process (2)
// Run a user provided ‘callback’ (based on the offending task) (3)
// If we have a file system: (4)
// Store information about the cause
// Do we restart the task/process? (5)
// Yes, Restart the task/process
// Alert a user (6)
// No, Reset the system (7)
}
(1) The system designer needs to determine what to do when a fault occurs. At a minimum, the offending task must be terminated, but do you also terminate the other tasks in the process? There might not be a single answer, and, in fact, it can depend on which task caused the fault. As a result, the MPU fault handler should be designed to perform different operations based on the task or process that triggered it.
(2) The offending task (or process) being terminated might own resources (kernel objects, buffers, I/Os, and so on) that would need to be released to avoid affecting other tasks/processes. The RTOS is aware of some of these resources and can automatically release them.
(3) The task that caused the fault might control actuators or other types of outputs that should be placed in a safe state to avoid harm to people or assets. A user-defined callback should be provided by the embedded system designer to take care of system-specific actions. The callback is stored in the task’s control block (TCB) during task creation. To improve system safety and security, a task should only be created during startup, while the CPU is in privileged mode, and a task should only be deleted at run-time due to a fault. Since the TCB resides in RTOS space, the callback would not be accessible from user code, therefore preventing potentially unsafe and unsecure code from invoking the callback, either unintentionally or maliciously.
(4) If the embedded system has some form of data storage capability, you might want to log information about the fault, such as the nature of the offending task, the values of CPU registers, actions taken, etc.
(5) Depending on which task caused the fault, it could be restarted and the system would recover from the situation.
(6) If the system is able to recover and if the system contains a display, it might be useful to alert an operation. Also, if the system has network connectivity, notifying the service department and (preferably) the development team can help avoid the issue in future releases.
(7) If the system cannot recover, there might be no other choice than to reset the system.
The MPU process table can be altered to include a per-task callback that can be called from RTOS context switch code upon detecting a fault. Of course, if all tasks need to perform the same operation upon a fault, you can either not use this feature or have the callback for all the MPU process tables point to the same callback. Most likely, the latter option is the most flexible and might be a preferred choice for a system designer because it offers greater flexibility for future releases.
That being said, you will probably need to consult your RTOS provider to determine if this feature is available.
Recommendations
Run User Code in Non-Privileged Mode
It’s possible to use the MPU and still run all the application code in privileged mode. Of course, this means the application code would be able to change the MPU settings and defeat one of the purposes of having the MPU. Initially, running the application in privileged mode might allow easier migration of your application code. At some point, though, most of your application code will need to run in non-privileged mode and you will need to add the SVC handler.
ISRs Have Full Access
The processor switches to privileged mode whenever an interrupt is recognized and the ISR starts. Since PRIVDEFENA in this case is set to 1, ISRs have access to any memory of I/O location anyway. You simply don’t want to reconfigure the MPU upon entering an ISR and reconfigure it back upon exit, so ISRs should be considered system-level code and should be allowed to have full access.
Also, ISRs should always be as short as possible and signal a task to perform most of the work needed by the interrupting device. Of course, this assumes that the ISR is kernel-aware and that the task has a fair amount of work dealing with the interrupting device. For example, processing an Ethernet packet should not be done at the ISR level. However, toggling an LED or updating the duty cycle of a pulse-width-modulation (PWM) timer might be done in the ISR.
Prevent Code Execution from RAM
Most MPUs allow you to prevent executing code out of RAM and, as a result, limit code injection attacks. Preventing code execution for peripheral devices may seem strange, but it doesn’t hurt to protect against hackers who might look for ways to get into your system.
Limit Peripheral Device Access to its Process
You should set aside one or more MPU regions to limit the access of a process to only its own peripherals. In other words, if a process manages USB ports, it should only have access to USB peripherals or peripherals related to the needs of the USB controllers, such as DMA.
Limit RTOS APIs
The system designer must determine which RTOS APIs should be available to the application code. Specifically, do you want to prevent application code from creating and deleting tasks or other RTOS objects, such as semaphores, queues, and so on, after system initialization? In other words, should RTOS objects only be created at system startup but not during run-time? If so, the SVC handler lookup table should only contain the APIs you want to expose to the application. However, even if ISRs run in privileged mode and so have access to any of the RTOS APIs, a good RTOS should prevent the creation and deletion of RTOS objects from ISRs anyway.
Allocate RTOS Objects in RTOS Space
Task stacks are located within a process’ memory space. However, RTOS objects (semaphores, queues, task control blocks, and so on) should preferably be allocated in kernel space and accessed by reference. In other words, you don’t want to allocate RTOS objects in a process’ memory space because that would mean application code can, whether purposely or accidentally, modify these objects without passing through RTOS APIs.
No Global Heap
It’s virtually impossible to set up an MPU to use a global heap (one used by all processes), so you should avoid those if at all possible. Instead, as previously suggested, you should allow process-specific heaps if a process requires dynamically allocated memory, such as Ethernet frame buffers.
Protect Access to Code
Although MPU regions are generally used to provide or restrict access to RAM and peripheral devices, if you have spare regions and are able to organize code (via linker commands) by processes, it might be useful to limit code access to code. This prevents certain types of security attacks, such as Return-to-libc [2].
Reduce Interprocess Communications
Just as tasks should be designed to be as independent as possible, processes should follow the same rule. Therefore, either processes don’t communicate with one another or you must keep interprocess communication to a minimum. If you have to communicate with other processes, set aside a shared region containing an Out and an In buffer. The sender places its data in the Out buffer and then triggers an interrupt to wake up the receiving process. After data is processed, the response (if needed) can be placed in the In buffer of the sender, and an interrupt can be used to notify the sender.
Determine what to Do when you Get an MPU Fault
Ideally, all MPU faults are detected and corrected during development. You should plan for faults to occur in the field either because of an unexpected failure or bug or because your system was subjected to a security attack. In most cases, it’s recommended to have a controlled shutdown sequence for either each task or each process. Whether or not you restart the offending task, all tasks within a process or within the whole system depend on the severity of the fault.
Have a Way to Log and Report Faults
Ideally, you should have a way to record (possibly to a file system) and display the cause of the fault to allow the developer(s) to fix the issue(s).
References
[1] Jean Labrosse, “Detecting Stack Overflows (Part 1 and Part 2)
https://www.micrium.com/detecting-stack-overflows-part-1-of-2
https://www.micrium.com/detecting-stack-overflows-part-2-of-2
[2] Wikipedia, “Return-to-libc attacks”
https://en.wikipedia.org/wiki/Return-to-libc_attack